FTIRでのデータ処理の アルゴリズムについて
今回は,FTIRでスペクトルに対して使用する,各種のデータ処理のアルゴリズムのうちいくつかについてご紹介します。これらはIRsolutionソフトウェアで採用されているものです。
スムージング
スムージングは,スペクトルの形状をより滑らかにする処理です。
例えば,S/Nの良くないスペクトルに対してこの処理を行うと,ノイズを小さくすることができます。これにより,ピークの分解は劣化しますが,ピークの有無やスペクトル全体の形状などがはっきりするため,未知試料分析などで定性情報を得る際に効果があります。
スペクトルをスムージングするということは,データ点ごとのスペクトル強度変化の度合いをやわらげるということに相当します。従って最も簡単には,スペクトルの各データ点の強度を,両隣のデータ点を含めた3点の強度の平均値で置き換えるというような方法でも,ある程度まで実現できます。下の図の点線グラフは,実線グラフの3点の強度平均で真ん中の点を置き換えたものですが,点ごとのスペクトル変化が小さくなっています。
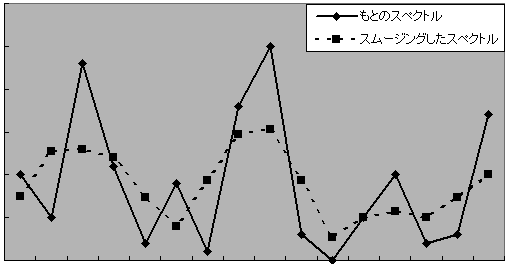
IRsolutionではもう少し複雑なアルゴリズムを採用しています。3点で平均をとる代わりに,指定したスムージング点数だけのデータ点において,点ごとに重み付けをしたファクターを掛けて合計した数値を使用しています。このファクターは,3次のSavitzky-Golay係数と呼ばれるもので,中心の対象データ点では大きく,周辺の点に対しては中心から離れるに従って減少する関数により決められます。スムージング点数は,IRsolutionのスムージングコマンドの画面で指定できますが,この値を大きくすると,広い範囲のデータ点の重み付けした平均をとることになるため,一般にはより滑らかで凹凸の少ないスペクトル形状となります。
補間
もともとデータ点の存在しない箇所のスペクトル強度を,付近のデータ点から内挿して求める処理です。最初のスペクトルよりデータ点は増加します。
この処理は,例えば,異なった分解で測定したためにデータ点間隔が異なるデータ同士を比較するときに使用します。適当な補間を行うことにより,それらのデータ間隔を等しく揃えることができるわけです。
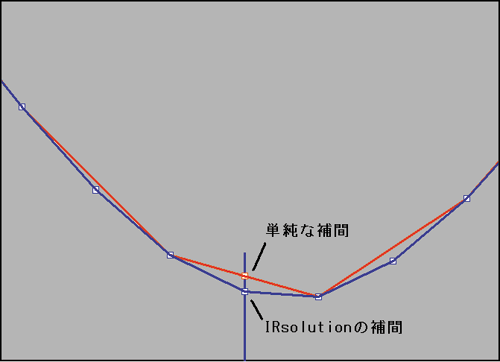
補間のアルゴリズムには,データのある2点を直線で結び,その上に新しい点を作るという単純なものもありますが,IRsolutionでは,Laplace_Everett法というアルゴリズムで計算しています。これは周辺の何点かの強度を用いて新しい点を作るという補間アルゴリズムです。つまり,求めようとする点の隣接する点だけでなく,その周りの点の強度も考慮に入れて,広い範囲での曲線の傾向を見て新しいデータ点を決めようとするものです。IRsolutionでは周辺4点を使用しています。
具体的には,スペクトル上にデータ点P0,P1,P2,P3が順番に並んでいて,それぞれの強度がI0,I1,I2,I3であるときに,点P1とP2を t:1-tに内分する点をPとすると,単純な補間では,その点の強度Iは
となりますが,IRsolutionのアルゴリズムでは,
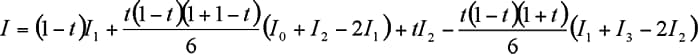
のようになります。
IRsolutionの補間機能は,データ間隔を1/2倍,1/4倍など特定の数に増やす場合だけでなく,自由な値のデータ間隔への変更をサポートしています。これは,旧データ点からカーブを計算し,指定の新データ間隔ごとに強度をとって新データ点を作成しているため可能となっているものです。そのため,もとのデータ間隔が,指定した新データ間隔の倍数となっていて,たまたま新旧のデータ波数が一致する場合があっても,一般にはそれらの強度はわずかに異なります。
補間はあくまでも数学的に強度値を予想する処理ですので,実際のスペクトル強度からの誤差があることにご注意ください。
ピーク検出
ピーク検出はスペクトルの特定波数にある吸収を見つける機能であり,試料物質の定性や定量のために使われます。IRsolutionでは,ピーク検出時にパラメータとして,しきい値とノイズレベル,最小面積を必要とします(これらの値は,対象スペクトルの縦軸が透過率表示のときと吸光度表示のときで異なりますが,働きは同様です。この項では吸光度表示を例に説明します)。
まず最初に,スペクトルの1次および2次の微分を計算して結果を保持しておきます。そしてその計算結果から,スペクトル上で1次の微分係数が正から負に変化する波数位置を検出して,それらをピーク候補とします(そこで極大値をとると考えられるので)。
それらのピーク候補から,吸光度がしきい値に満たないものを,まず除外します。その次に,ピーク候補点とその前後で1次微分係数の差を計算し,それらの絶対値が指定のノイズレベルに満たないものを,ノイズとみなして除外します。
それから,残ったピーク候補点の前後の点で,1次の微分係数が負から正に変化し,かつ,その点での2次微分係数が負であるような点を探します。そのような点が見つかれば,それはピークの前後にある「谷」であると判断します。谷が見つからない場合はピークではないとしてやはり除外します。
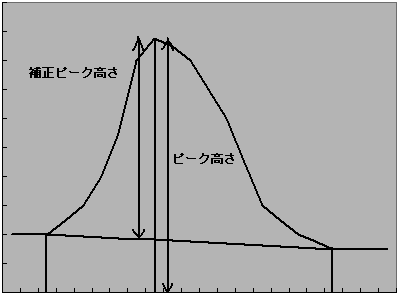
ピーク候補点前後に見つかった谷の点を,ベースラインとして結び,それから補正ピーク高さ・補正ピーク面積を計算します。これらの値が2つとも,指定のしきい値,最小面積より大きい場合,最終的にピークであると判断されます。
これらの動作は透過率表示のときも同様で,異なるのは,ピークの底(吸光度のときのピークトップ)の透過率やベースラインからそこまでの深さ,ピークと100%ラインやピークとベースラインの囲む面積などを代わりに使用することだけです。
膜厚計算
指定された波数範囲にある干渉縞の数から,赤外光の透過した膜の厚さを計算する機能ですが,アルゴリズムとしては,簡易なピーク検出とその応用と言えます。
通常のピーク検出同様,スペクトルから1次微分係数を計算し,その値が正から負に変化する箇所を検出します。対象となるスペクトルの特性上,細かいノイズレベルのチェックなどは行わず,それらをそのままピークとみなします。
そして,指定波数内に存在する最大・最小のピーク波数を検出し,その間のピーク数を数えます。それと設定された屈折率,入射角から次の式により計算が実行されます。
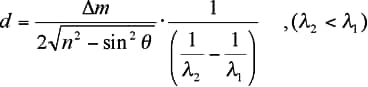
ただし,dは膜厚,λ1,λ2は指定波数範囲の両側にある2つの山または谷の波長,nは膜の屈折率,θは試料への赤外光の入射角,⊿mはλ1とλ2の間にある山の数です。
大気補正
測定したスペクトルから,大気中の水蒸気・二酸化炭素による吸収成分を差し引いて,これらによる影響を抑える補正機能です。IRsolutionではこの処理は,パワースペクトルの形式で表示されるバックグラウンドスペクトルの大まかな形状を算出し,それと元のバックグラウンドスペクトル上の吸収ピークを用いて,水蒸気・二酸化炭素ピークをキャンセルしています。
最初にバックグラウンドスペクトルの大まかな形状を計算します。これには,パラメータ設定画面で,水蒸気と二酸化炭素のそれぞれについて,高波数と低波数に分けて入力する数値が利用されます。これらの数値はスペクトル上での粗視化を行うための,波数で表したスケールファクターです。つまり,それぞれの波数領域において,その数値以下の小さな波数範囲での変化を無視することにより,細かい吸収ピークの無い概略の形のスペクトルを算出するものです。
なお,各波数範囲は次のようになっています。
水蒸気高波数3540~3960cm-1
水蒸気低波数1300~2000 cm-1
二酸化炭素高波数2250~2400 cm-1
二酸化炭素低波数600~740 cm-1
このようにしてできたスペクトルは,もとのバックグラウンドスペクトルから細かい凹凸を無くした包絡線状をしています。これらの間の差から,大気中の水蒸気・二酸化炭素の吸収ピークパターンを計算します。
さらに,同様にパワースペクトルで表したサンプルスペクトルについても,同様なピークパターンを計算し,バックグラウンドスペクトルから算出したピークパターンとの比をとります。この比によりスケーリングしたピークパターンをパワースペクトルから引くことにより,大気中の水蒸気・二酸化炭素の影響を除去したスペクトルを得ることができます(最終的なスペクトルはサンプル,バックグラウンドスペクトルの比として与えられます)。
このようにしてIRsolutionの大気補正機能は,バックグラウンドとサンプルの両方のパワースペクトルを使用して補正を実行します。そのため,補正することのできるスペクトルは,IRsolutionで測定した*.smfの拡張子で表される形式のものだけとなっています。
ライブラリ検索
ライブラリ検索のアルゴリズムの多くは非常に複雑です。限られた紙面上でそれらを網羅することはできませんので,ここでは典型的なライブラリ検索の動作を通して,比較的簡単な種類のアルゴリズムの説明を行います。
島津IRsolutionソフトウェアの検索機能は,何種類かの検索手法をサポートしていますが,最も一般的なものは「スペクトル検索」と呼ばれているものです。この「スペクトル検索」を実行するときには,いろいろと設定を行う必要があるのですが,アルゴリズムの選択もそれらの中にあります。
IRsolutionのスペクトル検索では,様々なアルゴリズムを選択できますが,それらのアルゴリズムの中では,”Difference”が比較的単純でなので,ここではそのアルゴリズムを使用した場合の動作について解説します。
IRsolutionでスペクトル検索を実行すると,最初に波数範囲の処理が行われます。これは選択機能ですが,スペクトル全体の代わりに,指定した波数範囲のみで試料スペクトルとライブラリスペクトルの比較を行うという機能です。この機能により,スペクトルの特徴的な部分のみを検索に利用することが可能となります。実際にはこの機能は,cm−1で表された波数範囲をスペクトルを構成するデータ点のインデックス(番号)に変換し,該当するインデックスのデータ点のみ,ソフトウェア内の比較機能部分に転送するという動作を行います。
次にスペクトルを強度で規格化します。これはIRsolutionの「データ処理」メニューの「規格化」と同等の処理で,スペクトルの形状を変えずに,最高の吸光度が1になるように全体に定数をかけるものです。
未知試料スペクトルは,一般にはスペクトル全体の大きさが,ライブラリスペクトルとは異なりますので,形状の適切な比較のためにこのような処理が必要となっています。
規格化により大きさがそろったら,設定波数範囲内にある全データ点において,未知試料スペクトルとライブラリスペクトルの強度の差の絶対値をとり,それらを合計したものを計算します。もし両者が完全に一致すれば,当然その値は0になるわけですが,実際には2つのスペクトルがどの程度似通ったものであるかの度合いにより値は変化します。この値にファクターを掛けて1000から引くことにより,完全一致で1000となるような指標(ヒットクォリティ)を得ます。この操作を使用する全てのライブラリスペクトルについて実行し,結果としてはヒットクォリティの高い順にそれらを並べたリストが表示されます。
他のアルゴリズムを使用したときも,全体としての動作はほぼ同様であり,未知試料スペクトルとライブラリスペクトルの差の絶対値をとる代わりに,差の2乗をとるなどの違いがあるだけです。
おわりに
以上のように,IRsolutionのデータ処理のいくつかについて,そのアルゴリズムを簡単にご説明しました。ふだんデータ処理機能を使用するときには,その詳細な働き方までは意識することはあまり無いと思いますが,アルゴリズムについて理解することは,処理の効果をよく認識することにつながります。データ処理を行うときに,時にはその有用性を意識してみてください。